前端开发中的数据流管理
发布时间:2023年3月12日
前端作为链接用户与数据的桥梁,在软件中扮演着 I/O 的角色,其中 O 代表着将后端存储的冷冰冰的数据以更好的形式展示给用户,I 代表着将用户的输入以合适的形式保存在系统内,借以推动相关数据的流转变更。虽然从工作内容来看,数据管理并不是前端工作的重点,但确实我们工作的出发点。
前端代码的组织方式从刀耕火种到现在经历了以下阶段:
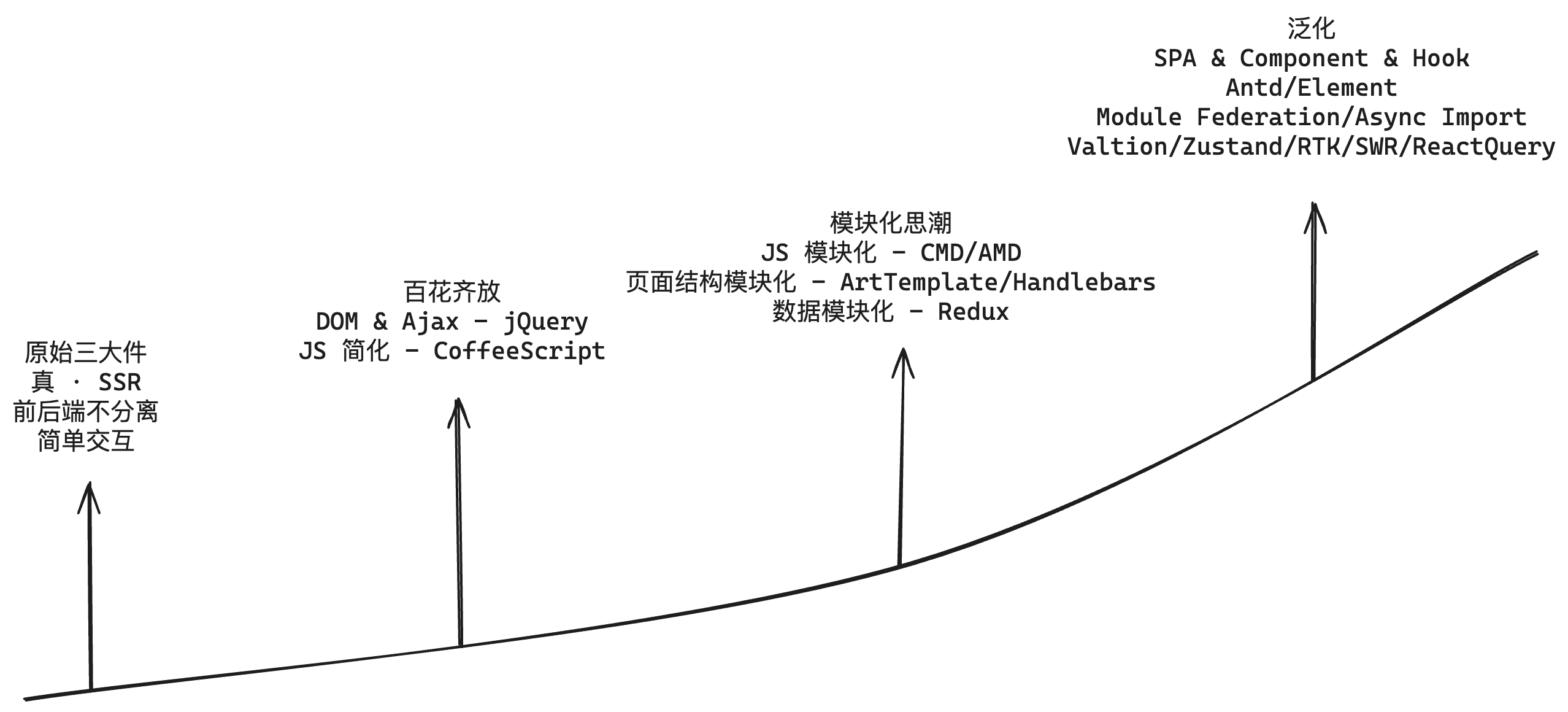
每一次时代的脚步,前端的代码组织方式都会发生翻天覆地的变化,但穿过表象,有一个东西一直没变,那就是:

状态语义的演变
前端代码组织逻辑上的变化主要体现在「模块化」层面,在我看来经历了以下阶段:
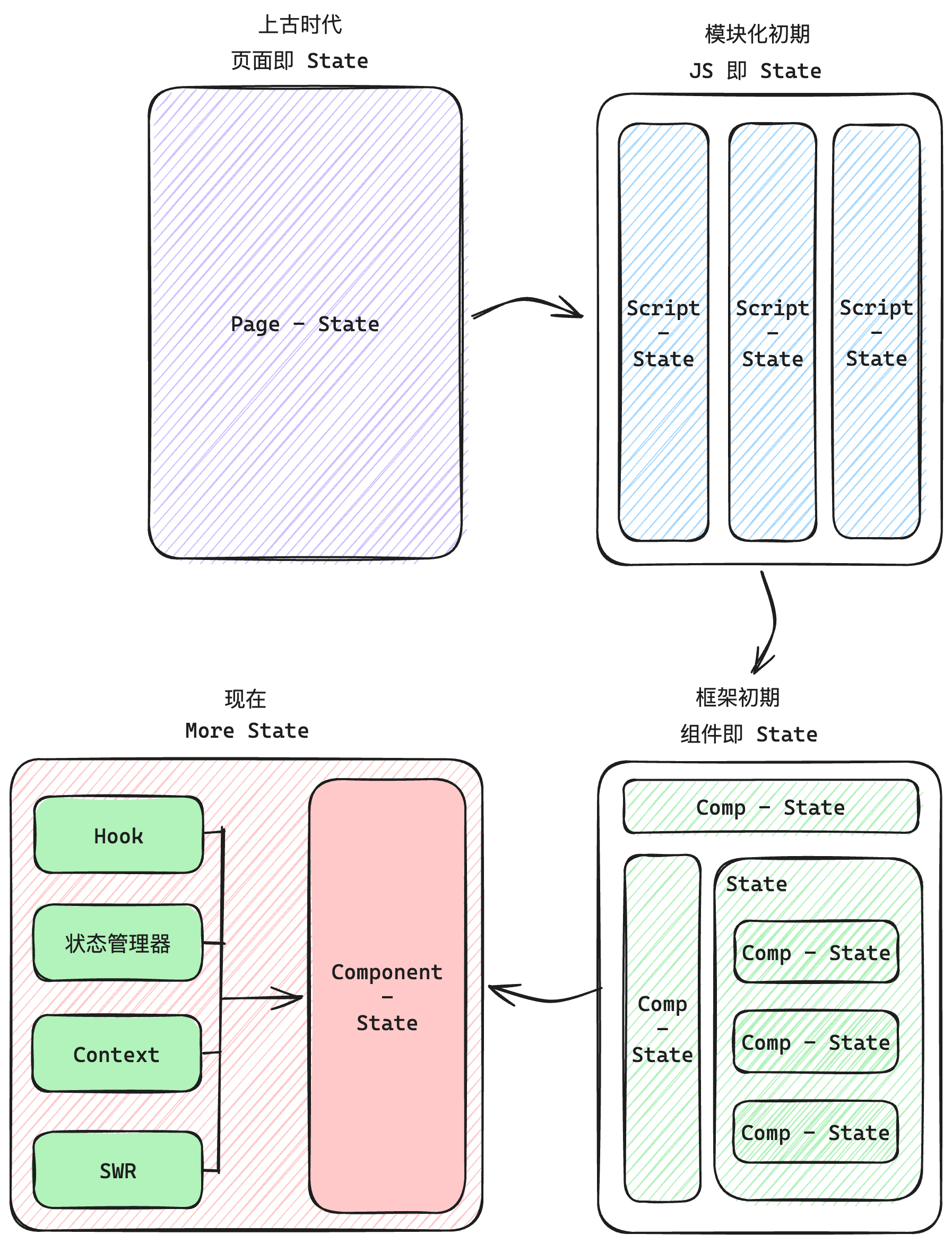
从上图中可以看出来,页面状态的变更经历了:页面级 - 模块级 - 组件级 - AnyWhere 四次变化,状态组织的变更代表着模块化程度的加深,而模块化的加深又代表着前端开发工作的精细化与复杂化,就像后端的微服务架构、前端的微前端一样,是时代的产物。
组件与状态
狭义上的组件状态的组织方法论各位已经有较多的体验,因此在这里就不多赘述
在这里想和大家讨论的问题是:如何更合理的拆解广义上的状态,以帮助我们更好的组织代码逻辑
在编写组件的时候,我们经常会处理这类问题:哪些状态是组件内部的(内源) & 哪些是外部传入的(外源),因此这么看来一个组件的状态总共由两部分组成:
- 内源状态:组件自身的状态及其衍生数据(origin state & compted),可以视为内聚状态
- 外源状态:外部关联状态(props & global state),可视为耦合状态
因此一个好的组件的数据流也应该具备「高内聚低耦合」的特征,下面拿一个业务中常见的场景举例:
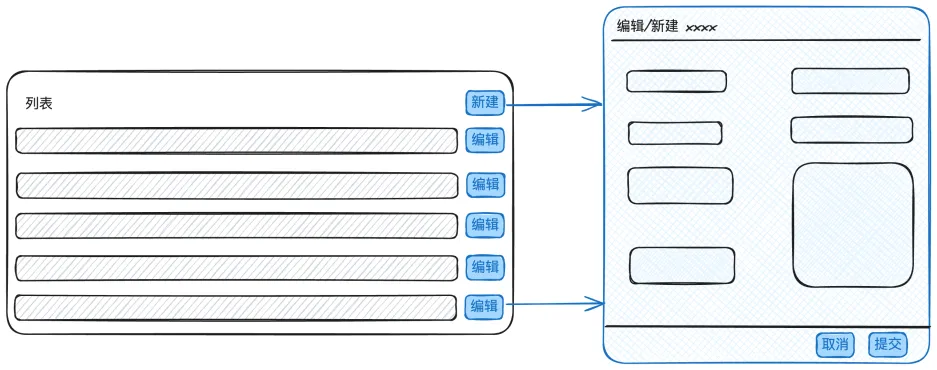
在上图中有一个列表,通过点击新建/编辑按钮可以唤起一个对应的弹窗组件,这个场景下会出现几个问题:
- 列表的数据如何传递给组件,props 或指令方式
- 弹窗的显隐状态由谁控制,编辑/新建状态由谁管理
- 点击提交时的具体请求是由列表组件触发还是弹窗组件触发
- 数据提交后如何触发表格数据的更新
上面的问题很多很细,实际上我们总结来看问题的本质还是 —— 如何确定状态的归属。我们可以将涉及的状态简单罗列一下:表格的 dataSource;弹窗的标题、显隐状态;需要回填的表单数据等
在组织这些状态时,我们也有两种方式:受控与非受控。受控意味着父组件需要接管子组件的状态,会导致父组件的状态中耦合有子组件才需要关心的状态,组件职能混乱,因此在实际开发中,我更倾向与使用非受控的方式去实现这套功能,其数据流与回调设计如下逻辑:
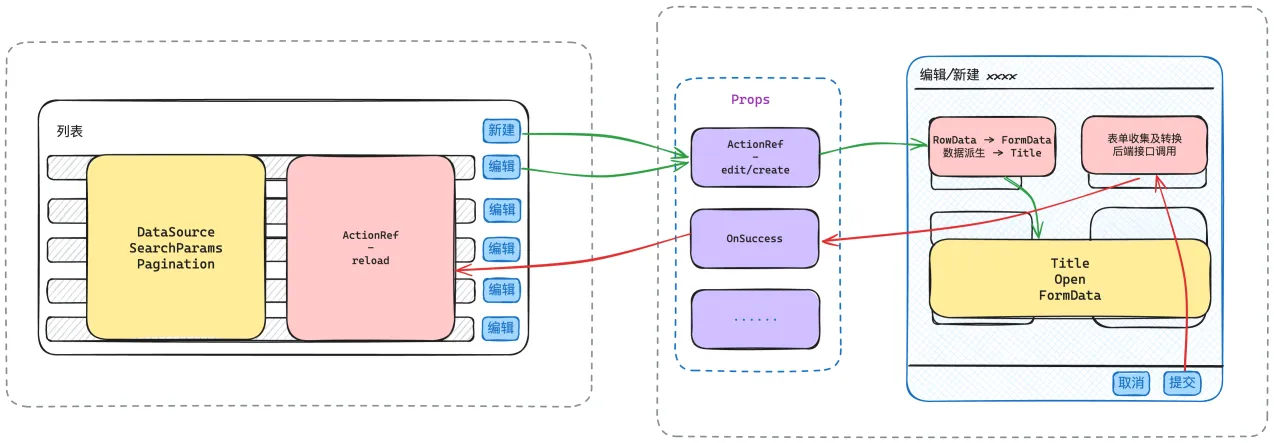
在上图的设计中,根据不同组件负责的功能,对状态进行了合理的分类,将状态的影响范围控制在组件内部,提高了数据的有序度,实现「上帝的归上帝、凯撒的归凯撒」;同时,针对一些必要的回调操作或数据流动,通过指令(ActionRef)的传递,可以避免对其他组件内部逻辑的感知,同时指令中也可以传递一些 用后即焚 类数据(比如:表单的RawData),减少无意义的数据留存等。
状态管理
谈到状态管理,想必大家都有很多的实践经历,目前市面上有众多的解决方案

再加上
- React 内置的
context、useReducer、useSyncExternalStore - 基于请求的库:
swr、react-query等
另外还可以和 immutable.js 结合衍生出更多的用法……
all right,我们手里有一大堆工具去敲一颗钉子
结合我在工作使用过的众多状态管理方案及迁移的实践,我开始思考:
- 我们在选择一个状态管理器的方案时,到底在纠结什么?是不是希望选出一个银弹?
- 从一大堆状态管理器中选择出一个「最合理」的时,对比的内容在一个维度吗?有多少场景是凭空造出来的?
- 老技术一定要重构成新潮的方案吗,性能不好是技术问题还是方案问题?带来的收获究竟是技术层面的还是心理层面的?
在实际场景中,每个人在选择一个状态管理方案时,其实是非常主观的,社区里也有一些不错的文章
每一个状态管理方案有着不同的心智模型,其解决问题的出发点都是不同的:有些希望全局共用一个 Store;有些希望你将状态分类拆解成多个的 Store;有些希望你按照最小复用粒度组织状态;有些希望你按照业务可复用的逻辑组织状态;而 React 又想让你使用它内置的方案。
从实际在业务中落地来看,任一状态管理器可能都能覆盖我们的业务场景,因此我觉得相比于选择一个合适方案,更重要的在于如何组织我们需要管理的状态。
在个人的实践中,将需要通过状态管理器解决的场景分为以下几类:

那么针对这些不同类型的状态,也有着不同的解法:
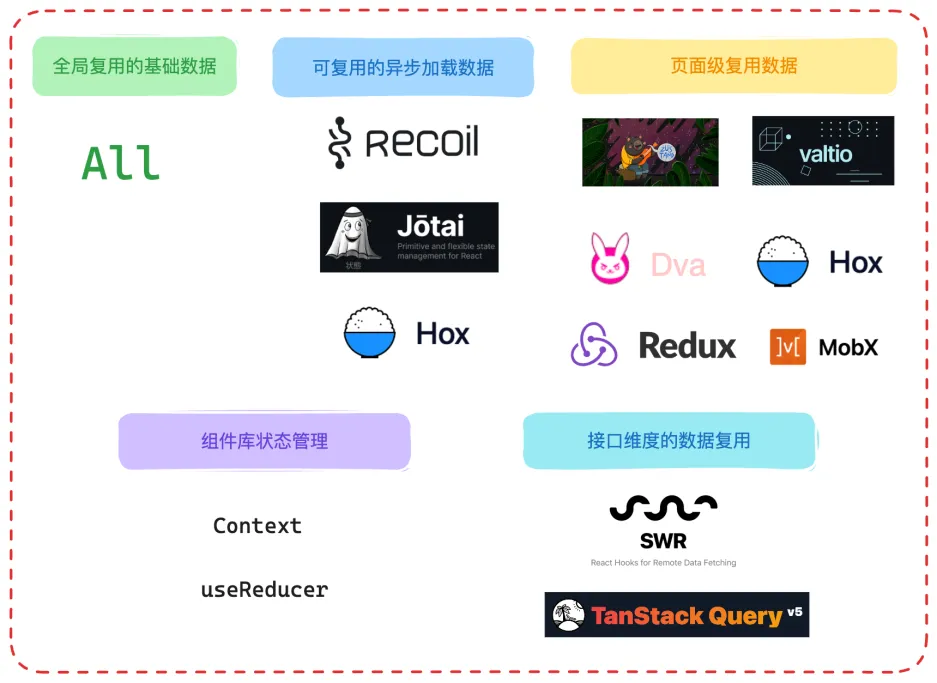
透过不同场景下的技术选型的表面去看其本质时,选择一个解决方案时,考虑的顺序应该为:
- 这个数据是否真的有复用场景吗?
- 自带的 context / useReducer 是否满足需求,是否真的需要引入一个或多个状态管理器
- 这份数据的性质是什么:
- 全局使用的基础数据:用大 Store 组织还是拆解成多个原子状态
- 有复用场景的异步(懒加载)数据
- 具体页面下多组件共享状态
- 对异步请求数据作缓存重复使用
- 项目中现在及未来可能需要管理的共享状态都有哪些,是选择一个大而全的还是根据场景去选择不同方案
- 选择的状态管理器的上手难度如何,数据及动作组织的心智模型是什么
当然,我们完全可以选择一个大而全的方案去覆盖所有可能的场景,但在部分场景下总是会有一些拧巴,比如:一个公司组织结构懒加载数据的管理,如果用原子化的方式去管理整个心智模型会很简单,定义一个结构树,查询&插入节点即可,而用基于 store 的库时总有杀鸡用牛刀的感觉。
正如前面讲过的,在状态管理的方案上,每个人的选择都是主观的,每种方案的设计思路不同,自然有各自的擅长与不擅长,像 redux 这类看似很古老的技术,在 github 上仍在保持着高频率的更新,官方也推出了拥抱 hook 的 redux-toolkit,而暂停维护了的 dva 也是可以在 Function Component 内继续使用,在组件库里也可以用 useReducer 实现一个简易的 redux store。
一个思虑完备的技术选型可能只是我们在状态管理上迈出的第一步,重要的永远是如何更好的组织我们的数据流。
数据/事件驱动
在上图中的业务场景中,Table 与 Modal 存在一些联动的行为,比如:
- 点击 「新建/按钮」触发弹窗的打开
- 点击弹窗的「提交」后触发表格的搜索
同时可能在项目开发中,我们会在全局挂一些通用的组件,如下图中的结构组织:
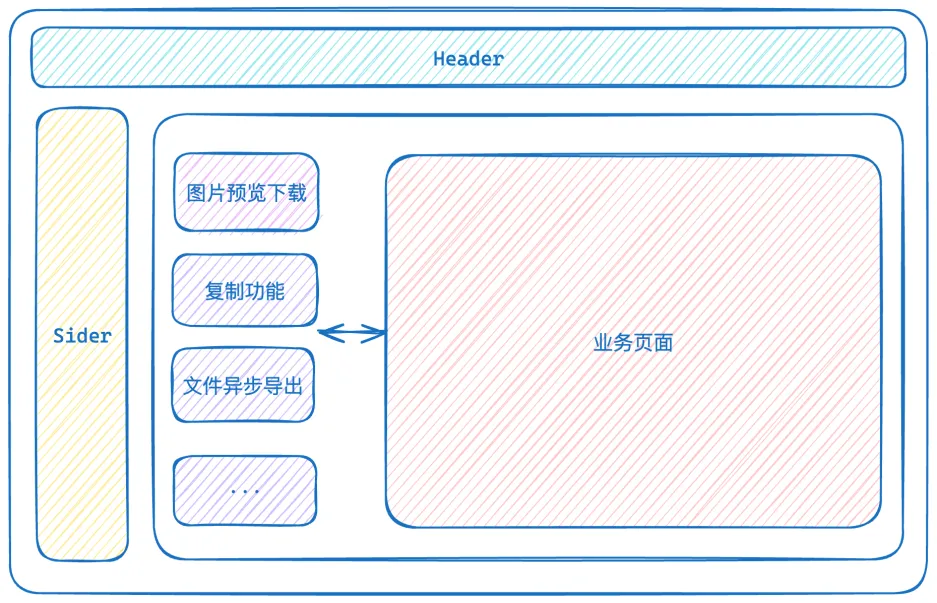
当在业务页面中需要使用到全局挂载组件的功能时,会有两种驱动模式:
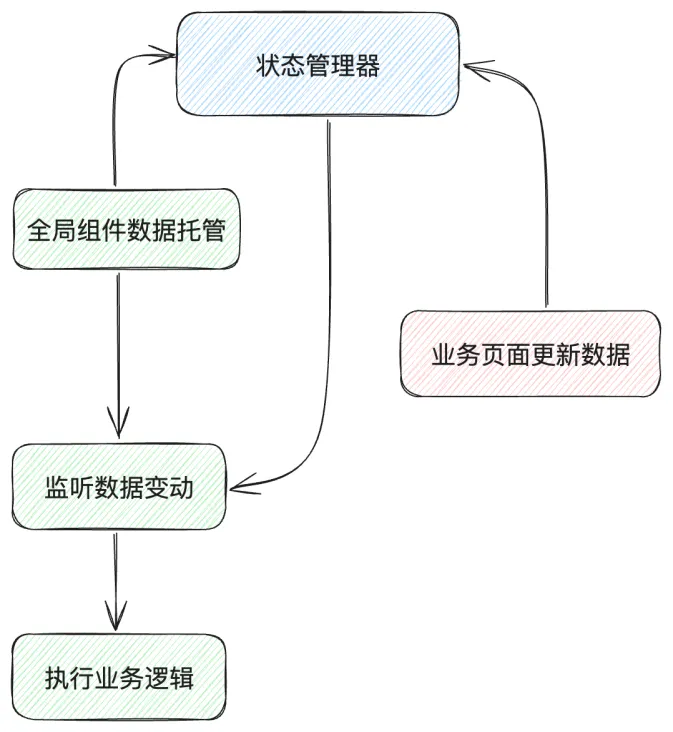
如上图所示,对于两者的差异总结如下表:
| 驱动类型 | 基础依赖 | 全局组件视角 | 业务页面视角 |
|---|---|---|---|
| 数据驱动 | 依赖于跨组件的状态共享 | - 依赖于数据的变动 - 是数据变动的副作用 - 主动执行 |
需要感知全局组件挂载在状态管理中的数据并能更新 |
| 事件驱动 | 依赖于共用的事件总线 | - 依赖于注册事件的触发 - 被动执行 |
需要感知全局组件的事件类型并主动触发 |
两类驱动逻辑在底层依赖、代码组织方式各不相同,同一个业务场景可以用任意方式实现,驱动方式决定着页面中的数据流动逻辑,选择更合理的驱动逻辑可以提高代码组织的合理性。